
By Darshan Joshi, Chief Technology Officer, CYTRIO
Companies have always run on intelligence. But the difference today is that intelligence is available via data. And we’re not short on data. Businesses collect a lot of data, and the rising number of transactions is making sure we will continually be drowning in data.
Yet, actionable intelligence — the type that can make companies agile and resilient — is still hard to find. This has made companies invest in tools and platforms to crack open the intelligence hidden within the bits and bytes, turning them into gigantic data processing entities.
This data-driven transformation has also changed the role of the chief technology officer (CTO). He or she is no longer employed to deploy the right technologies or keep the IT “lights” on. Today’s CTOs now have a shared role in ensuring companies get the most out of their data.
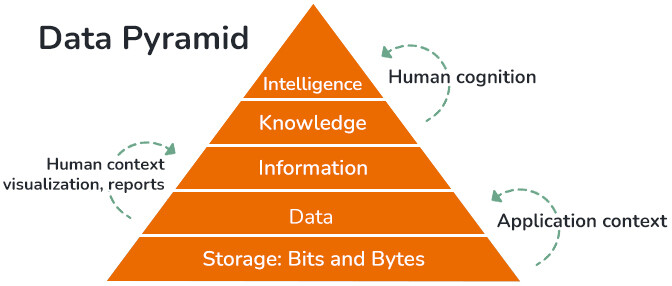
Data pyramid
When CTOs view data, they see a pyramid. Each bit or byte starts life in data storage, the lowest base layer. Storage becomes data in the context of application. Above it lies information, and then knowledge. At the pinnacle lies intelligence. A decade ago, CTOs would have been more concerned with ensuring that the storage layer had ample room, was backed up, and remained optimized.
Today, that base layer is bloated with data. Applications, sensors, and machines are pouring more data into the storage layer. But thanks to cloud storage, companies can now hold all that data without breaking the bank.
The challenge is that holding all that data is not enough. To the untrained human mind, interpreting data is not simple. For example, humans can’t understand grocery sales data in spreadsheet data but can easily digest “ice cream sales increase on hot days” or the information in sales trendline charts for a given store.
It’s the task of the data engineering and visualization teams to interpret this data and present it in a format that humans can understand. That’s when data becomes information. Humans with their cognitive capabilities and their domain knowledge then turn that information into knowledge. Knowledge is then used for actionable intelligence in a variety of ways, including planning, situational response, etc.
Data IQ
So how much intelligence is there in any given data set? Are you realizing all potential intelligence out of all your datasets? I call it the data quotient (DataIQ) of your datasets. It shows how much intelligence can be derived from the data now and in the future. Even if you are not able to realize all potential intelligence out of data, the latent intelligence is there. Someone, somehow has to bring the diamond out of the rough stone.
DataIQ (like human IQ) increases with volume of data – if it is good-quality data. DataIQ thrives in diversity. In data terms, that’s data variety. You can get more intelligence when you correlate or merge different data sets, which data scientists have known for years.
For example, if you as a grocery store owner have a customer’s purchase history data, it becomes even more valuable when you add the customer’s family size and information. That way, you can predict the customer’s buying patterns in the future.
Data with high DataIQ also offers intangible benefits. For example, clean data creates data trust, which allows users to be confident with the results and not second-guess them.
The CTO’s job is not just about finding this high-DataIQ data; they also need to ensure the data is secured and governed to reduce security and privacy risks associated with data. This is seeing CTOs working even closer with chief data officers and chief privacy officers, and in turn, creating a demand for proper tools and platforms that enables this collaboration.
DataIQ also increases over time as more data samples are available and you connect data with other datasets. Data lake models facilitate this because you saved all your data, including raw data, making it essential for CTOs to understand how these models impact DataIQ.
Lastly, DataIQ improves with human curation. Humans can identify promising findings for machine learning algorithms and direct them to focus on those.
For example, if a machine learning algorithm found 10 patterns in data (10 potential knowledge items), humans can direct the algorithm to focus only on five that they see as resulting in better intelligence, speeding up the intelligence creation process.
Facilitating this interaction between business experts and data science teams for human curation is becoming another CTO remit.
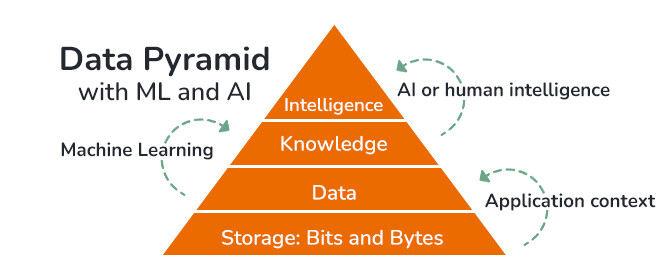
Human brain and data processing bottleneck
With so much data being produced, human brains may end up becoming the data processing bottleneck. There simply isn’t enough human brain cycles to convert tons of information and knowledge to intelligence. That’s when CTOs turn to machine learning and artificial intelligence.
With ML and AI, data does not go through information stages and human brains – bypassing the bottleneck. In this case, ML algorithms derive knowledge directly from data. This knowledge then can be used by humans. Knowledge derived by ML can also be used by AI to take automated micro-decisions – think bots – or major situational decisions in robotics.
How is the role of CTO changing?
With data affecting every part of the organization, companies see data management as a shared responsibility. After all, failure to grasp the right intelligence in time impacts business success.
It is also why the CTO’s role is broadening. Their expertise in nitty-gritty IT is becoming vital for data science teams to identify high-DataIQ data and make it available for decision-making and business innovation. Many are also working with data engineers to ensure the data pipelines are ready for the speed of AI-driven data ingestion.
Here are some key aspects of the changing CTO role:
- Be more data focused and not just technology focused. In the ML world, good quality data with good volume trumps good algorithms in the long run.
- Identify data sources with high DataIQ.
- Ensure these data sources are governed and secured.
- Employ the right tools, including ML and tools to maximize intelligence out of all datasets. In other words, gain all possible intelligence from datasets in the most efficient manner and as fast as possible, including real time.
The evolution of the CTO has only started. As companies look for better ways to find the real truths hidden in the expanding data universe, expect the demands on them to grow larger.
Bio
Darshan Joshi is co-founder and Chief Technology Officer at CYTRIO. He has more than 20 years of data and data management experience, having held SVP/VP of technology and engineering roles at industry leading data and data management companies such as Informatica, Symantec, and Veritas.





